【PR】 家電品の安さ、品揃えに自信あり!
【PR】 マジックトーカーズなど英語教材比較
【PR】 Windowsサーバをお探しなら、
|
【PR】 転職を成功させるインターネット活用術 【PR】 家電品の安さ、品揃えに自信あり! 【PR】 マジックトーカーズなど英語教材比較 【PR】 Windowsサーバをお探しなら、 |
||||||
・(序論)文字化けの発生メカニズム概論と解析方法安心の24時間サポート!! →WADAXレンタルサーバー
「ここではきものをぬいでください」。あなたは何を脱ぎますか? 「ここでは、着物を脱いでください」の意味に取れば、「着物」を脱ぐことになります。「ここで、履物を脱いでください」と取れば、靴やサンダルを脱ぐでしょう。このように平仮名だらけの文章は読みにくく、コミュニケーションにおいて誤解を招く可能性があります。 そこで、人間はコミュニケーションする際に、決まりごとを必ず持ちます。例えば、
「1」については、例えば20年ぐらい前になりますが、国語の教科書に載っていた文章が印象に残っています(細部は違うと思います)。「刑事は血まみれになりながら逃げる泥棒を追った。」という文章があったとして、「血まみれ」になっているのは、刑事でしょうか? 泥棒でしょうか? ここで句読点の重要性が出てきます。『刑事』が血まみれになっているならば、「刑事は血まみれになりながら、逃げる泥棒を追った。」とすべきでしょう。血まみれになっているのが「泥棒」であるならば、「刑事は、血まみれになりながら逃げる泥棒を追った」と。もしくは、句読点ではまだ分かりにくいので、完全に語順を変えて、「逃げる泥棒を、刑事は血まみれになりがなら追った」とするのではないでしょうか? 「3」については、例えば、玄関に「ここではきものをぬいでください」とあれば、「靴」のことであると判断するでしょうし、風呂場にその掲示があったのならば、「着物」を脱ぐでしょう。 文字化けも同じように言えます。コンピュータ上の世界では、究極的には2進数の世界であり、全ての文字列は0か1かの電気信号になりますし、もう少し人間に分かりやすく16進数にしたとしても、同じ文字列が、区切る場所によって意味が変わったりします。ですから、『どの読み方』をするのかということを定義したものが必要になってき、それこそが「文字コード」であると言えます。 文字コードには、日本で使われている主なものとしては、「Shift_JIS」「EUC-JP」「JIS(ISO-2022-JP)」「UTF-8」などがあります(これだけたくさんあるのは、歴史的な経緯のためであったり、それぞれ一長一短あるためです。)。例えば、JISでは、エスケープシーケンスというものが用いられて、2バイト文字とアルファベットなどの1バイト文字との切り替わりが分かるようにしています。句読点のような役割をしているのですね。
この宣言こそが、有名なメタタグであったり、後々何回も紹介します、htaccessによる文字コードの宣言だったりするわけです。繰り返しますが、この宣言がない場合、「このページにはShift_JISには存在しないはずの文字コードが現れているから、Shift_JISであるはずはない。この文字コードの現れ方はEUC-JPに違いない」と判断し、EUC-JPと判断したりするわけです。つまり、これはブラウザが「文脈」で判断していることになります。 ただし、人間でも文脈の読み間違いからミス・コミュニケーションがありうるように、文字コードでもそういう読み間違いが様々な理由から存在し、それが文字化けの原因になります。先述のように、異なる文字コード間でも、限られた文字コード領域を複数の文字コードが利用しているためにコードの重複が見られ、そのために有名な半角カタカナの文字化けのようなことが起こります。このホームページでは、まさしく、そのような読み間違いの原因になる現象をかなり豊富に、かつ詳細に検証しているつもりである。 一つ覚えていただきたいことは、「ここではきものをぬいでください」というものが、「履物」を脱ぐのか「着物」を脱ぐのかを論争する余地はあったとしても、そこで髪の毛を切ったりとかテレビを見るとか、全く別の言葉には解釈されることはないということです。つまり、文字化けであっても、化けるには化けるだけの理由や規則性があるのであって、むやみやたらに文字化けしているわけではないのです。それがブラウザのバグが原因であれ、私たちWebmasterの問題であれ、でです。 例えば、Shift_JISで半角カタカナの「アイ」は「0xB1B2」ですが、これはEUC-JPでは「渦」という漢字の文字コードになります。つまり区別がつきません。なので化けることがありますが、これが「朝(EUC-JPでは0xC4AB)」に化けたりはしません。化学反応と同じです。
<<文字コード一覧表に親しむことが、文字化け研究の第一歩>> WindowsではIMEのバージョンによって様々でしょうが、IME2002の場合、左の画像のようにIMEパッド(虫眼鏡がアイコンにあるもの)をクリックして表示されるポップアップの中に「文字一覧」というのがありますから、これをクリックすると、文字一覧を確認できます。その一覧表の中のそれぞれの文字にカーソルを合わせると、Shift_JISで「0x82a0」などと16進文字コードが表示されます。
また、当ホームページでは、より気軽に文字コードを調べることができる手段として、こちらのようなFlashを利用したURLエンコード(Shift_JIS版)を利用しているところが多くあります。URLエンコーダーやデコーダーはこちらで無料配布しています。利用法については順次、本文中で説明します。 次のページでは、「ネスケ4.Xで特定の文字(試・時・事・私など)が文字化けする場合」を取り上げます。
|
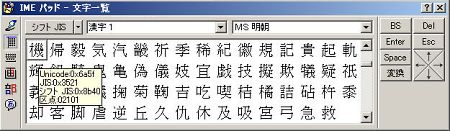 また、全ての文字には、16進数で「0x82a0 = あ」(0xはその後に続く文字列が16進数であることを示す符号。『あ』の場合、1バイト目が82、2バイト目がa0)などという文字コードが存在します。これらの値は、左の画像のような「IMEパッド 文字一覧」やMacなら「ことえり」などの一覧表で参照できます。また、この16進値は、全く同じ文字であっても、「Shift_JIS」の場合と「EUC-JP」の場合とでは違ったりします。これは、文字コードによって1バイト目はここからここまでの領域を使う、2バイト目はここからここまでの領域を使うとか決め事があるためです。実際には、文字コード間で重なりがあるため、誤認識なども起こりえ、これを回避するために、予め「この文章は○○語で書かれています」みたいな宣言をブラウザに対して行います。ブラウザは原則として、その宣言を信じて、その通りに解釈して表示します。
また、全ての文字には、16進数で「0x82a0 = あ」(0xはその後に続く文字列が16進数であることを示す符号。『あ』の場合、1バイト目が82、2バイト目がa0)などという文字コードが存在します。これらの値は、左の画像のような「IMEパッド 文字一覧」やMacなら「ことえり」などの一覧表で参照できます。また、この16進値は、全く同じ文字であっても、「Shift_JIS」の場合と「EUC-JP」の場合とでは違ったりします。これは、文字コードによって1バイト目はここからここまでの領域を使う、2バイト目はここからここまでの領域を使うとか決め事があるためです。実際には、文字コード間で重なりがあるため、誤認識なども起こりえ、これを回避するために、予め「この文章は○○語で書かれています」みたいな宣言をブラウザに対して行います。ブラウザは原則として、その宣言を信じて、その通りに解釈して表示します。 なお、本ホームページを読み進む上では、WindowsやMacに付属する文字一覧表は必須になります。その使い方を説明して、本稿に入るとしましょう。(この文字一覧表では、並び方に癖があり、ほぼ、音読み順になっています。そのため、特定の漢字が文字化けする際に、特定の音読みの漢字に集中して現れたりするとこがあります。)
なお、本ホームページを読み進む上では、WindowsやMacに付属する文字一覧表は必須になります。その使い方を説明して、本稿に入るとしましょう。(この文字一覧表では、並び方に癖があり、ほぼ、音読み順になっています。そのため、特定の漢字が文字化けする際に、特定の音読みの漢字に集中して現れたりするとこがあります。) Macでは、「ことえり」の場合なら、右の画像の赤丸の部分をクリックすれば、シフトJISコード表が立ち上がります。ユニコード表やJISコード表の参照も可能です。Windowsと基本的に同じ並び方をしていますが、一部、Windowsには存在する漢字もMacでは標準では入っていない文字もありますし、逆にMacに存在してWindowsには存在しない文字もあります。これらは機種依存文字と言いますが、機種依存文字については、こちらの
Macでは、「ことえり」の場合なら、右の画像の赤丸の部分をクリックすれば、シフトJISコード表が立ち上がります。ユニコード表やJISコード表の参照も可能です。Windowsと基本的に同じ並び方をしていますが、一部、Windowsには存在する漢字もMacでは標準では入っていない文字もありますし、逆にMacに存在してWindowsには存在しない文字もあります。これらは機種依存文字と言いますが、機種依存文字については、こちらの