【PR】 冬のソナタで始める韓国語
【PR】 最新パソコンも100円販売!
イーモバイルならEMマーケット
【PR】 足の臭いにグランズレメディー
|
【PR】 ウイルスチェックサービスのあるレンタルサーバ 【PR】 冬のソナタで始める韓国語 【PR】 最新パソコンも100円販売! イーモバイルならEMマーケット 【PR】 足の臭いにグランズレメディー |
||||||
「半角カタカナを入力しないで下さい」は失格?!まず、この「半角カタカナ」という名称について考えてみます。半角カタカナというのは、正確な表現できないというのをご存知でしょうか? 「全角」に対して「半角」があるわけですが、これはフォントに依存します。こちらに違いがよく分かるような比較表を作成しました。この比較表を見ていただければ分かりますが、「MS UI Gothic」や「MS P明朝」のようなプロポーショナルフォントでは、半角カタカナでは全角カタカナの半分の幅ではありません。強いて言えば、「MS UI Gothic」で約80%カタカナ、「MS P明朝」で約70%カタカナになります。また、いわゆる半角カタカナは1バイトカタカナという場合があります。確かにShift_JISでは1バイトなのですが、EUC-JPでは8Eという制御文字が1バイト名について2バイトになります。ですので、1バイトカタカナという名称も、厳密に言えば正しくありません。正しくは、JIS X 0201のカタカナということになるのです。対して、いわゆる全角カタカナはJIS X 0208のカタカナになります。 また、半角カタカナといいながらも、実際にはカタカナでないものも、この領域には含まれます。「。」「・(中黒)」などの半角などです。顔文字などをよく利用される方は注意した方が良いでしょう。
このように半角カタカナはJIS及びUnicodeでも定義されており、したがって、どこかのベンダーが勝手に決めた機種依存文字などではありません。ですから、半角カタカナを機種依存文字と呼ぶのは間違いです。文字コード依存文字です。
The Kana set of JIS X 0201 is not used in ISO-2022-JP messages. とあります。つまり、「ISO-2022-JPでは、JIS X 0201のカナ(いわゆる半角カタカナ)は使ってはいけない」となっています。逆に言えば、仮に半角カタカナを使ったメールを送っているならば、それはISO-2022-JPではないということです。「半角カタカナでも実際メール送信できているよ」という場合は、それはメールソフトの方で別の規格(約束事。全角文字に強制修正したり、ISO-2022-JP以外の文字コードで送信している)に基づいて送信しているだけのことであり、もし、その約束事が理解できない別の会社のメールソフトで受信したならば、正しく受信できるとは限らないのです。つまり、メールに関しては、確実に半角カタカナを送受信できる共通規格がないのです。
また、「ネットスケープ4.Xで特定の文字(試・時・事・私など)が文字化けする場合」の章で説明しましたが、ネットスケープ4.Xで特定の文字が特定の条件下で文字化けする原因は、EUC-JPの半角カタカナとShift_JISの漢字の区別がつかないこと原因でした(この場合は、実際には半角カタカナを使っているわけではなく、ネットスケープ4.Xが勝手にそう思い込んでしまっているのですが、根本的には半角カタカナの存在を考慮した結果であるとも言えます)。 かくして、WEBでも半角カタカナは利用できないということになっています。しかし、ここで疑問が生じます。確かに、Shift_JISの半角カタカナだけの文章であれば、Shift_JISであると判断することはできませんが、あきらかにShift_JISにしか存在しないコードであったり、逆にEUC-JPにしかないコードを持つ文字もたくさんあるわけです。それらと総合的に判断すれば、Shift_JISの半角カタカナをEUC-JPのJIS漢字(もしくはその逆)と勘違いしたりすることは、ほとんど考えられないはずなんです。
そう考えると、会員登録画面などで、ユーザーに名前や住所などを入力してもらう場合に「半角カタカナは入力しないでください」という表現を実に多く見るのですが、あれは妥当なお願いでしょうか? Googleで検索すると「半角カタカナは入力しないでください」は579件(2003年6月10日現在)、「半角カタカナは入力しないで下さい」は284件ありました。 確かに、掲示板など不特定多数の人が利用するサイトで、一人のユーザーが半角カタカナを入力したがゆえに、そのユーザーの投稿と同じページの掲示内容がことごとく文字化けするということはありえます(メタタグ、HTTPヘッダー、.htaccessでの制御などが不十分な場合)。 ですから、決して見当違いなお願いではないと思うのですが、こういうお願いをしているサイトで実際に半角カタカナを入力した場合、どうなるのか、いつも気になります。お願いを書いていようが明記していなかろうが、プログラマーとしては半角カタカナを入力される危険性を常に考慮しておかなければなりません。これに限らず、危険なコードを入力される危険性を常に頭に置いておくのがプログラマーの仕事だと思いますので、半角カタカナの処理も入れるべきであると私は考えます。 話が少し逸れますが、メールアドレスは半角入力であることは当たり前ですが、ユーザーの中にはその区別がつかない人たちも実際少なくありません。IE限定ですが、スタイルシートで半角英数字しか入力できないようにしておいたり(ex. <input type=text name=email size=50 style="ime-mode:dsiabled;">)、あるいは、プログラム内でのエラーチェック時に全角英数字は自動で半角英数字に変えてあげるぐらいの処理は、技術上は何でもないはずです(サーバへの負荷を考えると別)。また、私自身一番腹が立つのが、住所の番地で半角英数字を入力するとエラーを出すサイトです。半角英数字が駄目なら、入力画面にそれこそ書いておいて欲しいし、そもそもなぜ半角英数字が駄目なのか、理解に苦しむことがあります。百歩譲って、半角英数字が駄目なら、半角英数字が入力されていたら、エラーメッセージを出すのではなく、全角英数字に自動変換してくれないだろうかと思ってしまうのです。全角英数字と半角英数字の対応関係はあまりにも明白であり、「2」が「1」だったりすることはないのですから、エラーチェック時にこれぐらいはやってほしいです。 電話番号や郵便番号だって一緒です。ハイフンのあるなしでエラーにするぐらいなら、最初から入力ボックスを分けておくか、もしくは、自分が欲しいフォーマットにプログラム側で修正してもらいたいです。エラーメッセージの挙句、前のページに戻ると入力値が消えていて、腹が立った経験は誰にでもあると思います。もちろん、半角数字しか入るべきでないところに数字でないものが入っている場合(コマンドと解釈されるようなメタ文字など)は排除すべきですが、全角数字「2」を半角の「2」に変えてあげるのは難しくないはずなんです(サーバへの負荷を無視できる場合)。 話が逸れましたが、半角カタカナ(JIS X 0201)の場合も、全角カタカナ(JIS X 0208)との対応関係は明白な訳ですから、簡単に変換できるわけです。例えば、PHPならmb_convert_kana関数で、またCGI(perl)ならjcode.plなどを利用することで半角カタカナ→全角カタカナの変換は数行のコードで可能です。もちろん、POSTもしくはGETで送信されたデータの文字コードが何であるかが分からないとどうしようもないといことになりますが、「通常は」、Shift_JISのページから飛んでくるデータはShift_JISです。EUC-JPのページから飛んでくるデータはEUC-JPです。 ここで、「通常は」と書いたのには訳があります。それは、次章の「EUC-JPのページからShift_JISのデータがPOSTされるケース」で検証しますように、特定の条件下で不具合が発生するUA(ユーザーエージェント。ブラウザ)があるからです。また、「文字コードとセキュリティ」の章で説明しますが、悪意のあるユーザーが故意に文字コードを変えて送信してくるケースもないとは言えないからです。 そのような理由から、出来る限り、サーバ側で受信したデータの文字コードを決め付けることなく、受信したデータで判別するのがベターです。PHPならmb_detect_encodingで可能ですし、CGI(perl)でもjcode.plやjcode.pmで可能です。名前や住所を入力させるフォームで、半角カタカナやNEC選定IBM拡張文字しか使われていないというケースは通常はありえないと思いますが、もし、どうしても文字コードの判別に失敗するようであれば、<input type=hidden name=dummy value="あいうえお">をフォーム内に埋め込み、dummyの値の文字コードを見てみるというのも手です。
いずれにせよ、文字コードさえ分かれば半角カタカナを全角にすることは難しくないのですから、プログラムで変換してあげるのが親切だと思います。 |
|
<<半角カタカナより機種依存文字の方が厄介>> 私見では、「半角カタカナは入力しないで下さい」より「機種依存文字は入力しないでください」の方がより重要であるように思います。「機種依存文字は入力しないでください」をGoogleで検索すると、たったの104件(「下さい」は25件)でした。一方、「半角カタカナは入力しないでください」は579件(「下さい」は284件)でした。かなりの差があります。また、「機種依存文字は入力しないでください」の例示には、「ローマ数字などの機種依存文字」「特殊記号などの機種依存文字」という表現は見られますが、「
文字コードの判別の難しさという観点から半角カタカナだけがたたかれる傾向がありますが、実際はShift_JISにおけるNEC選定IBM拡張文字(0xED40〜0xEEFC)やIBM拡張文字(0xFA40〜0xFC4B)だって、EUC-JPともろにかぶっているわけです。例えば、Shift_JISの
もちろん、これらの文字は機種依存文字です。ですから、わざわざ例示するまでもなく、使用してはいけない文字なのですが、これらの文字が機種依存文字であることを知らないユーザーは少なくないと思われます。もちろん、「田中太郎」さんが「
(参照)▼ OSF 日本ベンダ協議会 (OSF/JVC) 推奨
という形で変換テーブルが提唱されています。ただ、全てのOS・プログラム(バージョンの違いなどを含む)などでこれが実装されているかは別問題ですし、またMacでは、そのままでは表示されないということには代わりがありません。画像にするか「 ページ全体をUTF-8で作成しても、Mac版ブラウザでは実装上の問題があり、うまくいきません。画像で表示が最も普遍的な方法であると言えます。このように、半角カタカナより機種依存文字の方がずっと厄介だと思います。半角カタカナは、プログラムの方で全角にすることが可能ですが、機種依存文字はかなり大変な問題です。 次のページでは、「EUC-JPのページにあるフォームからShift_JISのデータがPOSTされる」という不可解なケースについて検証します。
|
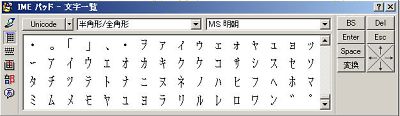 しかしながら、これではほとんどの方にはちんぷんかんぷんだろうと思いますし(私自身、ようやくその呼称の問題点を最近理解できたばかりです)、また国際規格であるUnicodeでも、互換性のために設置された「Halfwidth and Fullwidth Forms」という領域(U+FF00〜U+FFEF。日本語では『半角形/全角形』と訳されているようです。右画像参照)にこのカタカナが定義されています。また、これらのカタカナ一つひとつに、英語での名称があり、「HALFWIDTH KATAKANA LETTER SMALL A」(半角カタカナの小さいア)だったり「HALFWIDTH KATAKANA LETTER A」(半角カタカナのア)します。HALFWIDTHとは半角を意味しますから、国際的にも利用されている名称であるため、本稿では「半角カタカナ」という名称を用います。
しかしながら、これではほとんどの方にはちんぷんかんぷんだろうと思いますし(私自身、ようやくその呼称の問題点を最近理解できたばかりです)、また国際規格であるUnicodeでも、互換性のために設置された「Halfwidth and Fullwidth Forms」という領域(U+FF00〜U+FFEF。日本語では『半角形/全角形』と訳されているようです。右画像参照)にこのカタカナが定義されています。また、これらのカタカナ一つひとつに、英語での名称があり、「HALFWIDTH KATAKANA LETTER SMALL A」(半角カタカナの小さいア)だったり「HALFWIDTH KATAKANA LETTER A」(半角カタカナのア)します。HALFWIDTHとは半角を意味しますから、国際的にも利用されている名称であるため、本稿では「半角カタカナ」という名称を用います。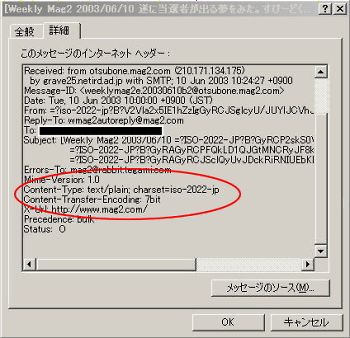 では、なぜかくまでも半角カタカナは嫌われているのでしょうか? なぜ、半角カタカナはインターネットでは使えないとされているのでしょうか? まず、メールで使えないのは、メール送信の際に一般的に用いられる文字コードはISO-2022-JPという文字コードです。ISO-2022-JPは7ビットの文字コードであるため好都合なのです。皆さんのところに届くメールのプロパティを見てみると、どのようなエンコードで送信されているか分かります(左画像参照)。このISO-2022-JPが半角カタカナを除外していることが、メールでは使えないとされている根拠になります。このことを定義した
では、なぜかくまでも半角カタカナは嫌われているのでしょうか? なぜ、半角カタカナはインターネットでは使えないとされているのでしょうか? まず、メールで使えないのは、メール送信の際に一般的に用いられる文字コードはISO-2022-JPという文字コードです。ISO-2022-JPは7ビットの文字コードであるため好都合なのです。皆さんのところに届くメールのプロパティを見てみると、どのようなエンコードで送信されているか分かります(左画像参照)。このISO-2022-JPが半角カタカナを除外していることが、メールでは使えないとされている根拠になります。このことを定義した 」の場合は「?」になります。)、Mac版ネットスケープ4.7及び6.0では「?」が表示されます。Mac版ネットスケープ7.02では、何も表示されず、その一文字が完全に消えてしまいます。(いずれもMacS9.22でのテスト。)
」の場合は「?」になります。)、Mac版ネットスケープ4.7及び6.0では「?」が表示されます。Mac版ネットスケープ7.02では、何も表示されず、その一文字が完全に消えてしまいます。(いずれもMacS9.22でのテスト。)