【PR】 バイオリスニング体験談
【PR】 ターボセルでセルライト対策
【PR】 Adobe Photoshop Elements 8 日本語版 Windows版
|
【PR】 マジックリスニングで12時間英語耳 【PR】 バイオリスニング体験談 【PR】 ターボセルでセルライト対策 【PR】 Adobe Photoshop Elements 8 日本語版 Windows版 |
||||||
「痴」「稚」が一杯。英語サイトを作ったら文字化け【COREPRESS Cloud(コアプレスクラウド)】10日間お試し無料
 英語サイトを覗いていて、日本語に出くわしたことはないでしょうか? 「痴人」「痴女」の「痴」、「幼稚」の「稚」、「溺れる」の「溺」、などです。文字化けするんだったら他の字でも良さそうなのに、何とも恥ずかしくなるような文字が出てくる場合があります。(右の画像は私がダミーで作成したもので、文法は正しいかどうかは分かりません。)
英語サイトを覗いていて、日本語に出くわしたことはないでしょうか? 「痴人」「痴女」の「痴」、「幼稚」の「稚」、「溺れる」の「溺」、などです。文字化けするんだったら他の字でも良さそうなのに、何とも恥ずかしくなるような文字が出てくる場合があります。(右の画像は私がダミーで作成したもので、文法は正しいかどうかは分かりません。)この文字化け、(海外サイトを頻繁に訪れる人には)かなり頻繁に現れます。試しに、Googleで検索してみます。
(参照)▼ 「痴」「稚」「溺」での検索結果 なぜ、海外サイトなのに、漢字が使われているのでしょうか? Googleの検索結果では確かに漢字が現れていても、実際にリンクをクリックしてそのページを見てみると、確かに漢字が現れている場合と、そうでない場合とがあります。 ブラウザで実際に表示させた場合に、文字化けが現れる場合と現れない場合がある理由については後述しますが、まず「痴」の正体を探ります。いくつかの検索結果を比較研究してみます。
|
|
では、なぜGoogleの検索サマリーはiso-8859-1のホームページをShift_JISのように誤認したり、また私たちがブラウザでそのページを表示させた場合に、文字化けが発生するのでしょうか? 結局は、「Googleの検索サマリーが文字化けする」の章で説明したことと同じなのですが、メタタグの指定が不適切であることが原因です。
Googleの検索結果に「痴」「稚」「致」などが現れるサイトを開き、HTMLソースを確認してみると、
例えば、ダブルクォテーションであれば、英語圏でも「“」ならぬ「"」(ダブルクオテーション)や、「’」ならぬ「'」(シングルクォテーション)は存在し、実際、多くの海外サイトではこちらを使われているのですが、一部のサイトでは、私たち日本人が見ると文字化けする方のキー入力(Shift_JISには存在しないコード)をされているようです。そして、メタタグの指定もないため、日本語圏の我々が見ると文字化けして見えるというわけです。 そして、Googleではメタタグの指定が重要な要素を握るためサマリーが文字化けしていますが、IEなどのブラウザで表示させると、それぞれのブラウザの独自解釈によって正しく解釈できるケースが多いため、Googleのサマリーが文字化けしている場合でも、ブラウザ上では文字化けしないケースがあるのではと思います。これは、「Googleのサマリーが文字化け」の章で説明した「縺」「繧」などの大量出現文字化け(UTF-8の文書なのにShift_JISというメタタグを指定してしまうという致命的ミス)とはタイプが違うために、メタタグの指定忘れぐらいであれば、まだブラウザの方で知恵を働かせて、正しく表示させることができるということだと思います。 ここまで延々と説明してきて、私たちは日本語のサイトしか作らないから問題ないと思われていませんか? ただ、あなたのホームページが企業サイトであれば、English版を準備するということは、無いことも無いのではないでしょうか? 実際、上記の「痴」「稚」「溺」での検索結果(Google)を見てみても、いくつかJPドメインだったり、日本語の混じっているサイトも結構ありました。 例えば、そのEnglish版を海外の本社自身が準備したり、あるいは海外の翻訳会社などに製作してもらった際に、そのままアップすると文字化けするかもしれません。メタタグの指定などがないために、Shift_JISと解釈されてしまう可能性があるからです。これはWebmaseterであるあなたが、しっかりとチェックして修正すべき責任にになるのではないでしょうか? また、自身で英語のページを作成する際にはなおさらそうでしょう。Shift_JISに存在しないクォテーションを使う場合は、しっかりとiso-8859-1と解釈されるようにメタタグや.htaccessで指定すべきです。 この文字化けは、例えば、以下のようにすることで、純日本語環境下でも文字化けを再現できました。WindowsXP(IME2002)では、「かっこ」と入力しても変換候補に全角であれば半角であれ「‘’」「“”」は変換候補として表示されませんでしたが、文字コード表から「’(0x8166)」や「“(0x8167)」を入力し、それを秀丸を使って、「欧文」として保存しました。この際に、秀丸の方で自動的に「0x92」や「0x93」に置換してくれているのか、「文字コード変換できない文字が含まれているため、文字が失われる可能性があります。」というような警告もなく保存できました。この状態で文字コードの指定をメタタグなどでしっかりと指定してあれば、問題は起きませんでしたが、ブラウザが文字コードの解釈を間違えると「痴」や「稚」が現れました。また、、WindowsMe(IME2000)では、「かっこ」で変換すると「‘’」や「“”」が変換候補として表示されましたので、"より簡単に"文字化けを再現できるでしょう。 ですから、この「おたまじゃくし」のようなクォテーションを使わずに、Shift_JISでも問題なく使える「"」「'」を使用するのが一番無難です。もしくは、日本語が一切混じっていない場合ならば、メタタグでiso-8859-1としっかりと指定したり、今までに何回か紹介した.htaccessで文字コードを指定してあげると良いでしょう。もう一度書きますと、 例 AddType "text/html; charset=iso-8859-1" html ただし、この指定をすると、そのディレクトリー内のHTMLファイル全ての文字コードがiso-8859-1になってしまうため、日本語のHTMLファイルとは分けるなどの作業が必要です。もしくは、拡張子を専用に定義して、
例 AddType "text/html; charset=iso-8859-1" iso などとします。hogehoge.isoはこれで文字化けしません。ただ、これだと、拡張子で判別して自動巡回しているサーチエンジン用のロボットプログラムも多いと思われ、これだとサーチエンジン経由のアクセスをみすみす逃してしまうことになります。日本語ファイルは.htmlにし、iso-8859-1は.htmなどと分けるのであれば問題はないと思います。(なお、ご利用になられているホームページサービスによっては、.htaccessを許可していない場合もあります。その場合は.htaccessが利用可能なレンタルサーバを借りなければいけないかもしれません。.htaccessが利用可能なサーバはこちらを参照してください。) Shift_JISにない『半角』のダブルクォテーション「“」やシングルクォテーション「’」を日本語文書の中で何が何でも使いたいのであれば、「’ → ’」「“ → “」などとコードを直接指定する必要があります。Shift_JISには全角の「“(0x8167)」「’(0x8166)」しかありません(ただし、結局はWindowsの機能により、コード指定しても全角のクォテーションが表示されているように見えます)。このあたりは、「バックスラッシュ(\)」は全角の「\」で代用するかフォントの指定を英字フォントにするしかないのと事情は同じような気がします。 英語・日本語の混合サイトを作成しようと思えば、この「おたまじゃくし」のようなクォテーションは全角で表示せざるをえないのですが、これも不恰好です。そう考えると、日本語と英語の混合サイトを構築する際には、この「おたまじゃくし」のようなクォテーションは一切使わずに、「"」「'」で我慢するのが見栄え的にはすっきりすると思われます。その上でメタタグの文字コードはShift_JISを指定するのがbest solutionだと思います。
|
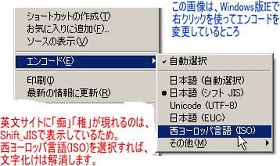 なお、サイト管理者としてではなく一般ユーザーとして訪問した英文サイトで、この種の文字化けにあったならば、ブラウザのエンコードを変更してあげればOKです。この手の文字化けは、ISO-8859-1の文章をShift_JISで読み込もうとしているために起こる文字化けなのですから、エンコードをISO-8859-1にしてあげればいいのです。Windows版IEなら左の画像のように、右クリックで、「エンコード」を「西ヨーロッパ言語(ISO)」にすれば良いのです。
なお、サイト管理者としてではなく一般ユーザーとして訪問した英文サイトで、この種の文字化けにあったならば、ブラウザのエンコードを変更してあげればOKです。この手の文字化けは、ISO-8859-1の文章をShift_JISで読み込もうとしているために起こる文字化けなのですから、エンコードをISO-8859-1にしてあげればいいのです。Windows版IEなら左の画像のように、右クリックで、「エンコード」を「西ヨーロッパ言語(ISO)」にすれば良いのです。